硬件结构
冯诺依曼模型
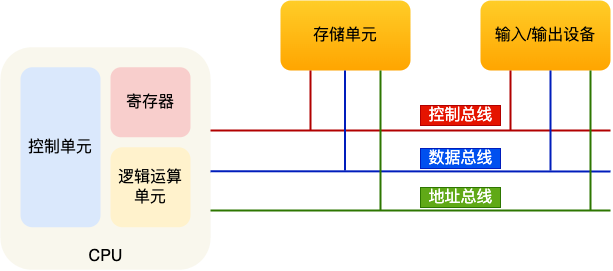
运算器、控制器、存储器、输入设备、输出设备
- 内存: 每一个字节都对应一个内存地址,内存的地址是从 0 开始编号的,然后自增排列
- 中央处理器: 64 位 CPU 一次可以计算 8 个字节,64位是 CPU 位宽
- 总线:
- 地址总线,用于指定 CPU 将要操作的内存地址
- 数据总线,用于读写内存的数据
- 控制总线,用于发送和接收信号,比如中断、设备复位等信号,CPU 收到信号后自然进行响应,这时也需要控制总线
当 CPU 要读写内存数据的时候,首先要通过「地址总线」来指定内存的地址,然后通过「控制总线」控制是读或写命令,最后通过「数据总线」来传输数据。
线路位宽
因为 2 ^ 32 = 4G,CPU 想要操作 4G 大的内存,那么就需要 32 条地址总线。
32 位 CPU 最大只能操作 4GB 内存
很少应用需要算超过 32 位的数字,所以如果计算的数额不超过 32 位数字的情况下,32 位和 64 位 CPU 之间没什么区别
CPU 时钟周期
比如一个 1 GHz 的 CPU,指的是时钟频率是 1 G,代表着 1 秒会产生 1G 次数的脉冲信号
每一次脉冲信号高低电平的转换就是一个周期,称为时钟周期
存储器
CPU Cache(SRAM)、内存(DRAM)、固体硬盘(SSD)、机械硬盘(HDD)
速度顺序:寄存器 > L1 Cache > L2 Cache > L3 Cache
- 寄存器:半个 CPU 时钟周期内完成读写
- L1 Cache:2~4 个时钟周期
- L2 Cache:10~20 个时钟周期
- L3 Cache:20~60 个时钟周期
- 内存:200~300 个 时钟周期之间
- SSD:比内存慢 10~1000 倍
- HDD:比内存慢 10W 倍
每个存储器只和相邻的一层存储器设备打交道
L1 Cache 通常会分为「数据缓存」和「指令缓存」,L1 Cache 和 L2 Cache 都是每个 CPU 核心独有的,而 L3 Cache 是多个 CPU 核心共享的。
直接映射 Cache
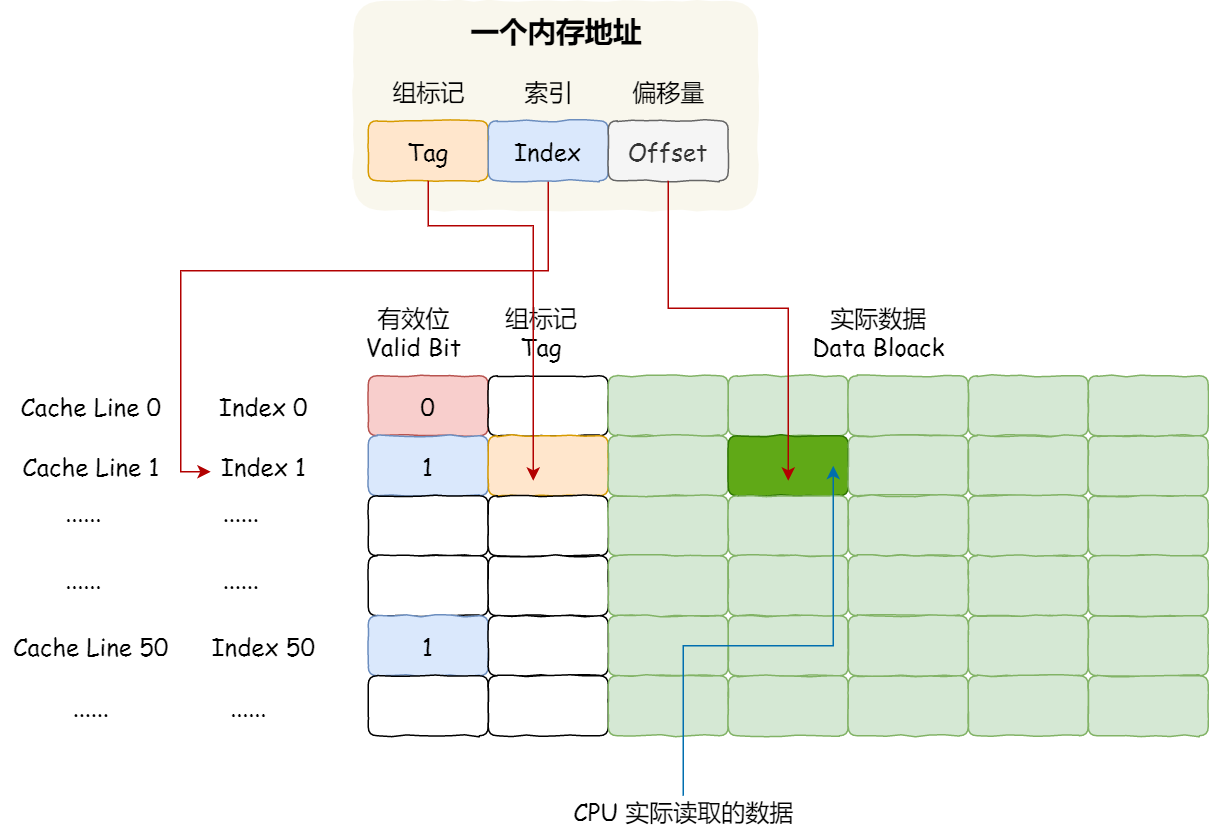
- 根据内存地址中索引信息,计算在 CPU Cache 中的索引
- 判断 CPU Cache Line 中的有效位(数据是否过期)
- 对比内存地址中组标记和 CPU Cache Line 中的组标记
- 根据偏移量读取
CPU 缓存一致性
写入数据时,怎么把数据写入内存:
- 写直达:把数据同时写入内存和 Cache 中,写入前会先判断数据是否已经在 CPU Cache 里面了
- 写回:只有在缓存不命中,同时数据对应的 Cache 中的 Cache Block 为脏,才会写入内存;如果不是脏数据会写入 Cache,同时把数据标记为脏的。
缓存一致性产生原因:CPU 是多核的,L1/L2 Cache 是多个核心各自独有的,多个核心操作同一个数据。
解决缓存一致性问题:
- 写传播:某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache
- 事务的串行化:某个 CPU 核心里对数据的操作顺序,必须在其他核心看起来顺序是一样的
具体实现是 MESI 协议
中断
中断是系统用来响应硬件设备请求的一种机制,操作系统收到硬件的中断请求,会打断正在执行的进程,然后调用内核中的中断处理程序来响应请求。中断处理程序,要尽可能快的执行完,这样可以减少对正常进程运行调度地影响。
软中断:将中断过程分成了两个阶段,上半部用来快速处理中断,下半部用来延迟处理上半部未完成的工作,一般以「内核线程」的方式运行
浮点数
负数用补码是为了在正数与负数在加减法运算时保持一致,不需要多余的判断
浮点数标准

1000.101 规格化表示成 1.000101 x 2^3,000101 为尾数位,3 是指数位
尾数位决定了浮点数的精度
指数位指明了小数点在数据中的位置